Microsoft offer a solution to this as part of their Azure offering. This blog will look at what Microsoft Azure's API Management product offers.
With APIM you can
- Ensure access to the API is only via APIM
- Set throttling policies based on users/groups
- Make users sign-up for access
- Generate and publish developer documentation easily
- Monitor traffic
And probably a whole lot more that I have not explored yet.
And all this can be done for multiple APIs all through a single endpoint. You simply need to have an azure account and create an APIM instance to get started.
I'll look at how to set up some of the things mentioned above, starting with establishing an APIM instance and pointing it to you already published API.
To create an APIM instance, go to the management portal for azure (I use the old style portal at https://manage.windowsazure.com/), select the APIM charm on the left

You will be presented with a list of your instances (but I guess you dont have any), and in the bottom left is the new button to create your first instance. Clicking this will open a banner with the options of what you want to create, there are no options, so just click create in third column

You will be asked for a URL, this is the endpoint that the world will use to gain access to your API, and a few other questions about where the instance will be hosted, who you are and your contact details, and if you select the advanced settings you can select a pricing tier, but that as the name suggests is an advanced topic, and this is a basic intro blog, so leave the pricing tier as Developer for now.
After that it will go away and spin up an instance for you which will take some time. At the end of this the list of APIM instances will be populated with a grand total of 1!!!
Next select the name of your new APIM instance and you will be presented with the quick start page, the only page that I honestly use within the azure portal in relation to the APIM instance.

The 'Publisher Portal' is the gateway to everything to do with the APIM instance. And out of interest the 'Developer Portal' is what the public will see if you tell them where to look for information on you API, i.e. where you can provide documentation.
To finish setting up your vanilla first APIM instance, go into the publisher portal and you will be presented with a dashboard with not a lot of data

The next thing to do is connect APIM to you existing API, which you do by clicking the add API button, and providing the details required. You need a name for the API, the URL for the API you made earllier, a suffix which will be used to distinguish between the APIs associated with the APIM instance and provide whether you want the access to the API (via APIM) to be allowed with or without TLS.
There are stil two steps to go. firstly defining the operations that can be accessed via the API. I.e. what verbs are allowed and for what URLs. Add operations such a GET users using the intuitive dialog

and finally you need to associate a product with the API. Products are in my opinion badly named. They represent levels of subscription to the API. By default 2 products are preconfigured, Starter and Unlimited, you can associate these or any other products with the API using the Products tab on the right of the screen.
After this your new APIM is ready to go.
The next thing you may wish to do is add a throttling policy to the API (or more specifically the product). You do this by selecting the policies option on the menu in the left, pick the combination of options you want to set the policy for (product, api and operation) and click the add policy option in the text box below. This will add a blank policy, and you can add the details of the policy using the code snippets on the right, so for a simple throttling policy select the limit call rate option, and this will add code to set a limit on the number of calls within a given time window. By default the starter product is limited to 5 calls in any 60 seconds, and 100 calls in a week
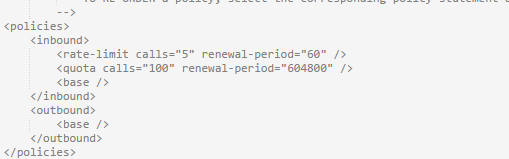
This gives you a flavour of what can be controlled with this.
The use of the products and policies in conjunction allows you to fine grain the access to the API and its operations in a way that is best fitted to you and your users.
The next thing I would look at is securing your API so that the rules set up in APIM must be followed. If people can go to the API directly, bypassing APIM, then these policies and rules are meaningless.
The simplest way to do this is to use mutual certificates between APIM and your API, and add code into your API to ensure that all requests have come from a source with that certificate. This can be done by going to the security tab on the API section of the publisher portal

then pick the mutual certificates option in the drop down. You will need to upload the certificate to the APIM instance, which can be done by clicking the manage certificates button. In terms of ensuring the request has come from a trusted source, that is a coding question, but for completeness, within a c# MVC webAPI system, add a message handler to the pipeline for the incoming requests by editing the WebAPIConfig class
public static class WebApiConfig
{
public static void Register(HttpConfiguration config)
{
// require client certificate on all calls
config.MessageHandlers.Add(new ClientCertificateMessageHandler());
}
}
public class ClientCertificateMessageHandler : DelegatingHandler
{
protected override Task<HttpResponseMessage> SendAsync(HttpRequestMessage request, CancellationToken cancellationToken)
{
bool isValid = false;
X509Certificate2 cert = request.GetClientCertificate();
if (cert != null)
{
if (cert.Thumbprint.Equals(RoleEnvironment.GetConfigurationSettingValue("ClientCertThumbprint1"), StringComparison.InvariantCultureIgnoreCase)
|| cert.Thumbprint.Equals(RoleEnvironment.GetConfigurationSettingValue("ClientCertThumbprint2"), StringComparison.InvariantCultureIgnoreCase))
{
isValid = true;
}
}
if (!isValid)
{
throw new HttpResponseException(request.CreateResponse(HttpStatusCode.Forbidden));
}
return base.SendAsync(request, cancellationToken);
}
}
I mentioned making users sign up for access. Well if they want to use your API we have just ensured tha their requests must be directed via APIM. The rest is built in. The products that you configured earlier have associated with them a subscription key that the consumer of the API must supply with every request. This ensures that every consumer of the API must have the subscription key. The developer portal provides a way to subscribe to your APIM and thus get a key. You can if you wanted restrict this so that you need to manually give access to every subscriber before they get a key, and that way you could monetize the access, but that is way beyond the scope of this article. Suffice to say they need to sign up to get the key or APIM will reject the requests.
The documentation aspect of APIM is probably something best explored yourself, I'm a techy and not best placed to explain this, however in summary you can document each operation on the page where the operation is created/configured, and the content of the description can take the form of html/javascript so you may wish to use some client side script to retrieve the documentation and manage the content externally.
<div id="dynamicContent"></div>
<script src="https://myserver/scripts/documentation-ang.js"> </script>
The final thing to look at is the analysis of traffic. Good news, you don't need to do a thing to configure this. Basic analytics are provided out of the box. If you require anything more complex than APIM offers for free you may wish to look at other products that could be bolted on to the system, but in general the data that is captured will provide you with a lot.
So in summary to that all, APIM offers an easy to set up and easy to configure interface to your API when you want to publish it to the world. It gives easy access to some very good security features and access control. There are many platforms out there that will host an API for you, but if you want to host you own somewhere, APIM offers a lot of what you need to consider before exposing your delicate little flower to the horror of the web.
Any questions or comments are welcome, and I will try to answer anything you ask. And please share this with everyone you know, and even those you don't know. Spread the word, the cloud is fluffy and nice!