Please don't be put off by the maths at this stage, I am simply looking to set the scene, I will not be delving into equations, rather the concepts of solving a class of problems. Essentially I had an equation something like:
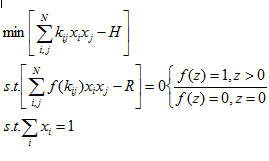
with this example being a simplified version in 2 dimensions, the real problem I was tackling had 19 dimension, but the concept is the same.
To give some real values to the problem for those of us who don't think in terms of pure mathematics, my simplest test scenario involved having a limit of N = 2 a matrix for k of

setting the values of H and R to be 0.5 and 0.95 respectively, we have
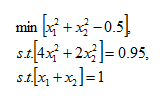
which on the face of it seems fairly straightforward. Brute force should make it fairly easy to solve, it can be reduced to a one dimensional problem, and very basic techniques could be used to solve. But without going to town on expanding the problem, imagine adding a third dimension, or simply increasing N to 3.
There are many techniques out there for solving such constrained non-linear minimisation problems, such as the use of Lagrange multipliers or numerical approaches like interior point interpolation. However I was, and still am interested in whether using genetic algorithms could be a fruitful avenue of investigation for this category of problem.
Genetic algorithms have a number of advantages over purely mathematical approaches. The problem of local minima being found being a key one, and from a computational point of view, the scalability of a GA approach drew me in.
What is a Genetic Algorithm
The idea behind a GS Approach is that given a problem that we have no idea of how to get to a good solution of, but where we know a good solution when we see it, we can explore the problem space finding progressively 'better' solutions until such a time as we are satisfied with the best solution tested.
In practice this means that we need to have a way to evaluate how 'good' a solution to the problem is. For the problem described earlier, we need a way to determine if for a given set of x the solution is acceptable, and how good a solution it is. As we have a constrained problem, only solutions for which the 2 constraint equations are satisfied are permissible. A simple measure of how good each permissible solution is would be how far from 0 the minimisation part resolves to.
Given this ability to evaluate how good a solution is (known as the fitness of the solution) the algorithm needs a way to generate new potential solutions in an educated manner to find ever better solutions, and then to iterate this loop.
The term genetic algorithm takes its origins from Darwinian evolutionary theory. A population of potential solutions exists, from which the fittest are selected, a further generation of solutions is born (variation in the population created via cross breeding and mutation), the weakest being culled, the fittest surviving, reproducing and evolving through the generations.
Given a broad enough initial population and sufficient generations, all corners of the problem space should be explored, with good, but not necessarily the best solutions not swamping out rarer but stronger strains.
Seems ideal?
Yes it does, calculating the fitness of a solution in this way is very fast and cheap. The calculation of the fitness of any solution is an atomic process, so a huge population is not a problem as we can easily scale out. So what is the problem and why aren't all mathematical problems approached this way?
One problem comes that a solution may be investigated that is a poor fit and discarded, another that is a fair but not excellent fit is returned in preference. over time we get a healthy population of fair solutions, but nothing good enough. Through mutation an cross breeding we will always continue to explore new solutions until the algorithm exits, however the details of the breeding and mutation limit the ability to find an 'ideal' solution.
The mere fact that we have discarded any possibility of a solution that violates the constraint equations out of hand means that we may be ruling out entire sections of the problem space that could evolve to yield a better solution.
A post that explores the idea of constraints that tighten through the generations is here, and suggests that ruling out solutions early in the evolutionary process is a bad idea, with solutions that violate the constraints becoming less favourable in later generations, but in early generations having the opportunity to influence the overall population.
How to implement a GA in .NET
A very good question, you could spend years writing the evolution, mutation, breeding and selection code. However, good news, there is a great framework that does the hard work for you, allowing you to concentrate on the problem you are really interested in. Using GAF allows you to concentrate on evaluating the fitness of solutions, defining how the mutations occur and how breeding is performed. With only the need to define 2 functions (evaluate the fitness of a solution and determine if we should stop evolving) you can solve a problem. A good introduction to the framework is given here with examples of problems you can solve.
The specific functions I used for this problem are:
private static double CalculateFitness(Chromosome solution)
{
var tol =1e-3;
var unfit = 0;
//need to calculate the proximity of the three equations to 0
var sum = solution.Genes.Sum(x => x.RealValue);
if (System.Math.Sqrt(System.Math.Pow(sum - 1, 2)) > tol) return unfit;
if (GetDeltaR(solution.Genes.Select(x => x.RealValue)) > tol)
return unfit;
return 1d-(GetDeltaF(solution.Genes.Select(x => x.RealValue)));
}
Where GetDeltaR and GetDeltaF calculate the difference between the result of the calculation and 0, the returned fitness is best at 1 and a solution is totally unfit if this evaluates to 0.
private static double GetDeltaF(IEnumerable<double> enumerable)
{
return System.Math.Sqrt(System.Math.Pow(GetF(enumerable) - TargetF, 2));
}
private static double GetDeltaR(IEnumerable<double> enumerable)
{
return System.Math.Sqrt(System.Math.Pow(GetR(enumerable)-TargetR, 2));
}
and
private static bool Terminate(Population population, int currentGeneration, long currentEvaluation)
{
return currentGeneration > 400;
}
The decision to terminate is simply based on the number of generations here, only because experience has told me that this will not reach a solution where delta F is less than an acceptable level.
So it doesn't solve the problem?
Not as such. With the fitness calculation above and the choice of breeding and mutation algorithms (I used the out of the box single point crossover breeding and swap mutation provided by GAF) a very good solution is not found. However it does find a solution, and with some minor tweaks to only the fitness evaluation (taking into account the ideas of relaxed constraints in the linked article) a solution with R = 0.943 and F = 0.235 can be found in seconds. Clearly this is not an ideal solution, but it is pretty good as a first stab.
For a problem such as this, the key to getting a good solution is choosing the correct mutation algorithm and breeding process. The swap mutation used simply swaps round the elements of the solution, they do not 'vary', so a solution of (1,2) could mutate to (2,1) but could not become (1.1,1.9). As we are dealing with continuous variables, the inability to mutate in this way will limit the proximity to the solution that we can get.
The crossover breeding takes 2 solutions, and uses part of each to produce a child solution (e.g. 1,2 and 3,4 could become 1,4) which is acceptable given a suitable mutation and sufficient generations to explore all evolutionary branches.
I am interested in developing a new mutation algorithm that modifies the elements (termed genes in genetic algorithm circles) of the solution and will detail this process in a later blog.
Suffice to say with little effort using GA to solve a complex mathematical problem is a good way to go. The effort to get a truly 'good' solution, may be a little greater, but to get a solution there is little effort. I have previously attempted to solve the class of problems described here using interior point interpolation with some success, however the starting point of these interpolations is key to finding a good solution as they are very prone to finding local minima. As such, a hybrid approach may be the answer, with GA selecting a range of potential starting points from which to interpolate rather than using either approach in isolation.
No comments:
Post a Comment